
Was „zeigt“ sich, wenn eine Maschine einen Text „liest“, also sequenziell Wort für Wort abarbeitet? Eher für didaktische Zwecke habe ich eine kleine Spielerei versucht (und dabei mit P5.js experimentiert):
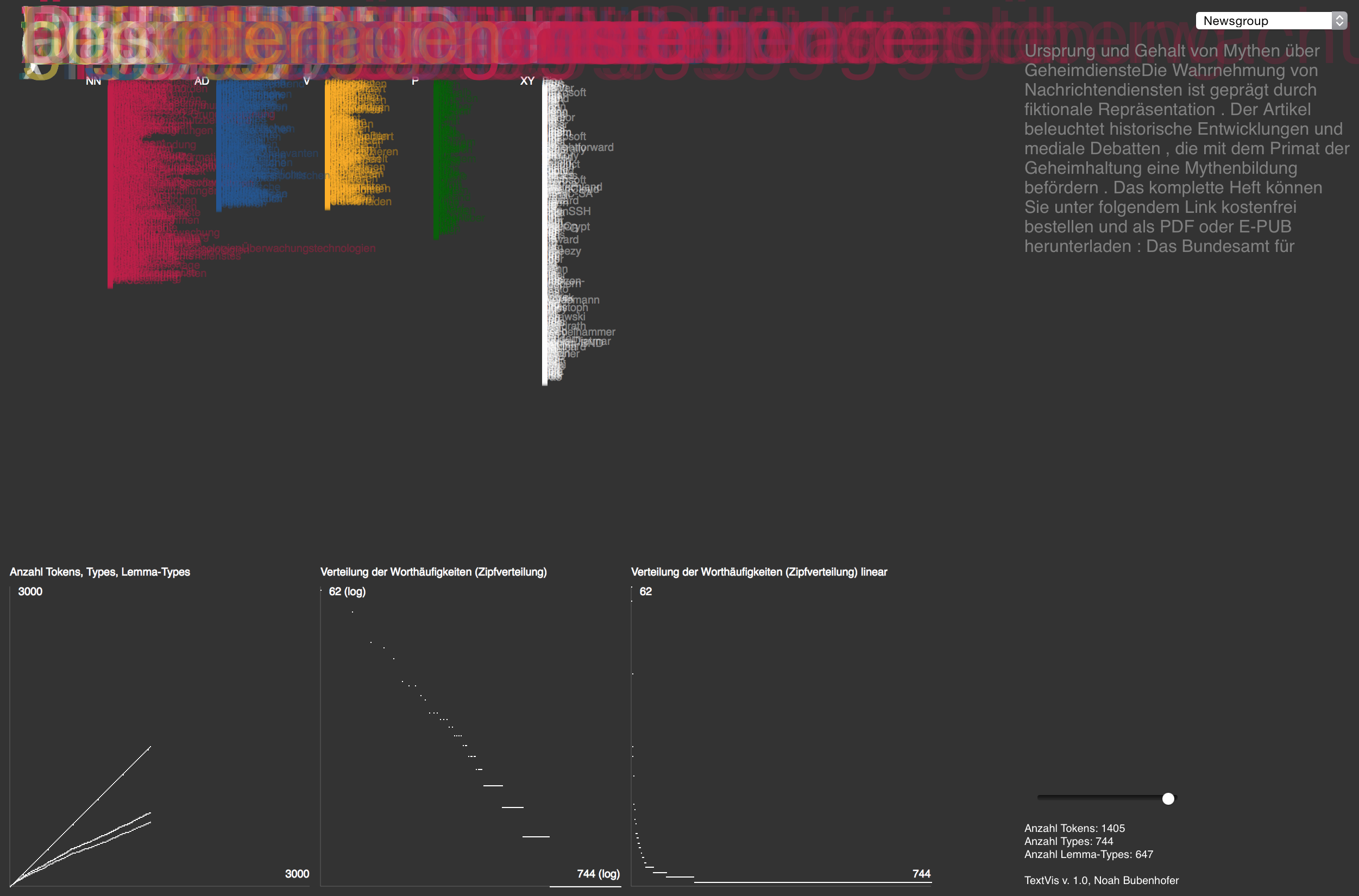
Screenshot TextVis 1.0
TextVis arbeitet einen Text Wort für Wort ab. Rechts werden die gerade bearbeiteten zwei Sätze aufgeführt. Jedes Wort wird ganz oben groß und in transparenten Farben abgetragen. Die farbliche Codierung unterscheidet fünf Wortklassen: Nomen, Adjektive, Verben, Pronomen/Partikeln und eine Restgruppe. Die prozessierten Wörter werden zusätzlich in fünf „Schubladen“ abgelegt, die entsprechend nach Wortaufkommen in der jeweiligen Kategorie wachsen.
Unten rechts wird die Anzahl der aktuell verarbeiteten Wörter aufgeführt. Links daneben werden einige statistische Maße aufgeführt:
- Ganz links kann man beobachten, wie sich das Type-Token-Verhältnis mit der Zeit verändert: Ganz zu Beginn sind alle Kurven deckungsgleich: Es gibt genau gleich viele Wörter (Tokens) wie unterschiedliche Wörter (Types). Mit der Zeit bewegen sich die Kurven auseinander: Die Anzahl der Types nimmt nicht linear zu wie die Anzahl der Tokens, die Kurve flacht immer stärker ab. Je länger der Text, desto unwahrscheinlicher wird es, dass wir noch neue Wörter antreffen, die wir nicht schon gesehen haben.
- Die anderen beiden Diagramme zeigen die Zipfverteilung im bereits bearbeiteten Text an: Die Types werden nach Frequenz absteigend in eine Rangfolge gebracht. Im Diagramm ganz rechts sieht man, dass es nur ganz wenige Wörter gibt, die sehr häufig im Text vorkommen, dafür eine lange Reihe von Wörtern, die nur ganz selten vorkommen. Diese Beobachtung entspricht der Annahme des Zipfschen Gesetzes, nach dem die Häufigkeit eines Wortes umgekehrt proportional zum Rang in der nach Häufigkeit abnehmenden Reihe ist. Das mittlere Diagramm zeigt die gleichen Ranghäufigkeiten, allerdings auf logarithmierten Skalen: Wenn das Zipfsche Gesetz stimmt, sollte sich in diesem Diagramm eine linear fallende Gerade ergeben.
Im Menü oben rechts können die jeweils ersten 3000 Wörter aus vier verschiedenen Korpora ausgewählt werden.
Die Erkenntnisse, die man aus der Visualisierung ziehen kann, ist alles andere als überraschend, jedoch sehr viel anschaulicher, als die Themen in Handbüchern abgehandelt werden. Das Mapping, also die Regel, mit der eine Wort- oder Texteigenschaft in ein grafisches Zeichen überführt wird, sehr simpel:
Wortlängen

[Wort] → [text – fontSize=60 – color=depending word class, alpha=.5] → Sichtbar wird: Häufige und seltene Wortlängen und Wortartklassen
Der sog. Alpha-Wert bei Farbfüllungen erzeugt einen Transparenzeffekt (siehe RGBA und Alpha Composing) und ist eigentlich keine besonders neue technologische Möglichkeit, wird aber in modernen HTML-Technologien (HTML5, SVG) immer besser unterstützt und deshalb wohl oft verwendet.
Worthäufigkeiten

[Wort] → [text – color=depending word class – position=depending word class and number of word in class] → Sichtbar wird: Anzahl Wörter pro Wortartklasse, Wortlängen separat nach Wortartklasse
Bildgebendes Verfahren?
Diese einfachen Visualisierungen reichen aus, um textstatistische Gesetzmäßigkeiten zu sehen, aber auch Abweichungen davon in bestimmten Korpora – ähnlich wie ein bildgebendes Verfahren in der Medizin, das im Röntgenbild den (gebrochenen) Knochen zeigt oder bei der Magnetresonanztomographie Körpergewebe.
So intuitiv verständlich solche Verfahren sind, so sehr verdecken sie, wie arbiträr und komplex gewisse Entscheidungen im Visualisierungsprozess sind. Im Fall von Textkorpora: Was ist ein Token? Wie wird eine Wortartklasse bestimmt? Welches Mappingverfahren verwende ich? In der Medizin sind bildgebende Verfahren in der Prozessierung der gemessenen Daten noch komplexer. Doch immer ist klar: Die Visualisierung ist nicht einfach ein Abbild des Gemessenen, sondern ein komplexes Zeichen, das eine „entwerfende Ähnlichkeit“ (Bauer/Ernst 2010:44) zum Gegenstand aufweist. „Bildgebend“ ist in diesem Zusammenhang deswegen ein geradezu naiver Ausdruck – die im Englischen (medical imaging) oder Französischen (imagerie médicale) gebräuchlichen Ausdrücke sind da etwas neutraler.
Bauer, Matthias/Ernst, Christoph: Diagrammatik / Einführung in ein kultur- und medienwissenschaftliches Forschungsfeld. Bielefeld : transcript, 2010