| Weitere Korpora | Daten analysieren |
| Web: Trafilatura | Medien: Swissdox@LiRI |
Download von Web-Daten mit Unix-Tools
Während eine Software wie Trafilatura viel Arbeit beim Download von Webdaten abnimmt, möchte man doch manchmal mehr Kontrolle beim Download. Oft werden Websites mit Content-Management-Systemen (CMS) oder aus Datenbanken heraus erstellt, so dass die Daten in einer sehr uniformen Struktur abgelegt sind und interessante Metadaten enthalten. Typisch dafür sind Online-Zeitungen, Blogs, Webforen etc. Hier wird beschrieben, wie mit Unix-Standard-Tools solche Daten heruntergeladen werden können.
Ein typisches Beispiel für Webdaten ist mein Blog Sprechtakel:
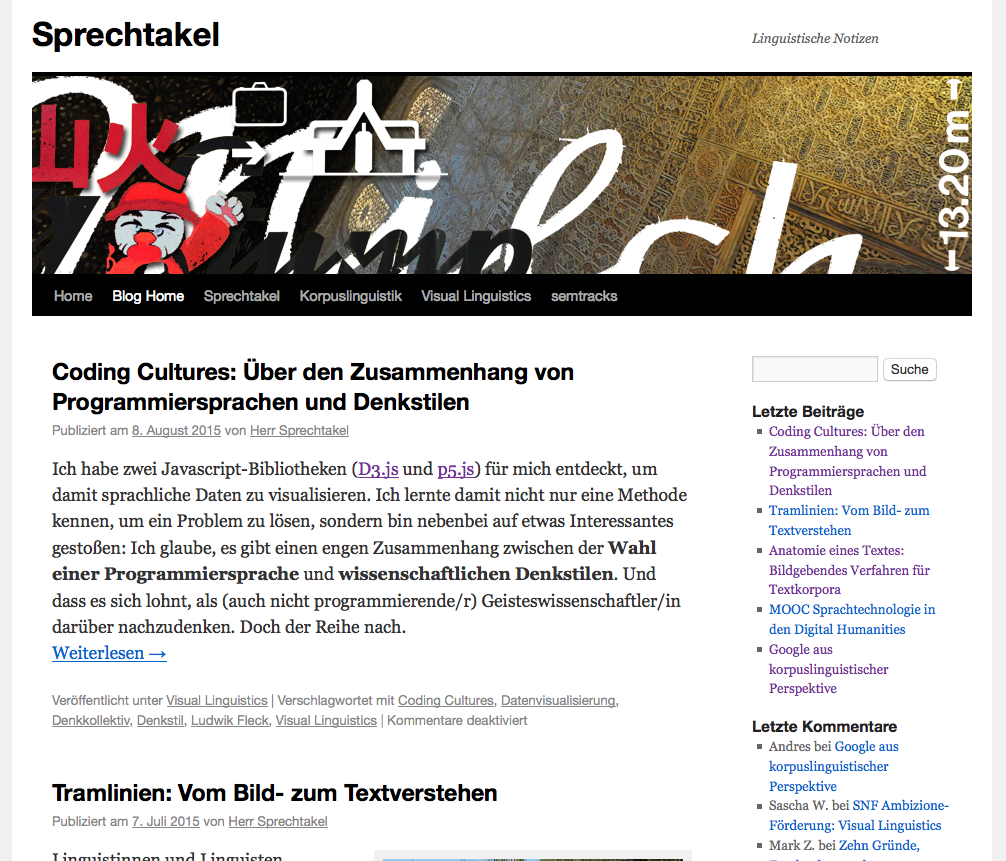
Auf der Übersichtsseite (Index) gibt es Anreisser für jeden Beitrag; der Titel und der Text "Weiterlesen..." verlinken zur vollständigen Ansicht. Ganz unten kann man zudem über "Ältere Beiträge" blättern und kommt zu weiteren Übersichtsseiten. Weiter gibt es auf jeder Seite Bereiche, die nicht zum eigentlichen Text gehören (Navigation, ggf. Werbung etc.) und die wir normalerweise nicht für ein Korpus berücksichtigen wollen. Nach diesem Prinzip sind ganz viele Websites organisiert.
Beim Blättern durch die verschiedenen Übersichtsseiten können wir zudem beobachten, wie sich die URL oben im Browser verändert. Auf der Startseite lautet sie noch:
https://www.bubenhofer.com/sprechtakel/
Beim Blättern jedoch verändert sich die URL systematisch:
https://www.bubenhofer.com/sprechtakel/page/2/ https://www.bubenhofer.com/sprechtakel/page/3/ https://www.bubenhofer.com/sprechtakel/page/4/ https://www.bubenhofer.com/sprechtakel/page/5/ ...
Die erste Seite könnte zudem auch über folgende URL aufgerufen werden:
https://www.bubenhofer.com/sprechtakel/page/1/
Die Systematik ist nicht auf jeder Website gleich, aber in sich konsistent. Das ist eine prima Voraussetzung, um die Daten automatisiert herunterzuladen.
Eine Möglichkeit ist die Verwendung einer Software wie Trafilatura. Hier wird alternativ der Download mit Unix-Standard-Tools beschrieben.
Download mit Unix-Standard-Tools
So strukturierte Daten können mit den Standardprogrammen auf Unix- oder Mac OS X-Systemen problemlos heruntergeladen werden. Einen möglichen Weg beschreibe ich im Folgenden – es gibt aber auch viele andere Wege, die Tools einzusetzen, sicher auch elegantere. Dieser scheint mir aber gut nachvollziehbar für Anfänger/innen:
- Zuerst laden wir alle Index-Seiten sprechtakel/page/1/ bis sprechtakel/page/11/ (momentan älteste Seite) herunter. Am einfachsten geht das mit curl:
curl -L https://www.bubenhofer.com/sprechtakel/page/[1-11]/ -o "sprechtakel_page_#1.html"Praktisch an curl ist die Platzhalter-Funktion: Mit [1-11] wird angegeben, dass alle URLs mit den Ziffern 1-11 heruntergeladen werden sollen. Der Parameter -L bedeutet, dass wir einer Weiterleitung folgen würden, wenn eine auftaucht (das ist bei der URL sprechtakel/page/1/ der Fall).
- In den heruntergeladenen Index-Seiten suchen wir die Links zu den Vollansichten der Texte; das sind die URLs der Texte, die wir downloaden wollen.
Wenn wir uns eine der heruntergeladenen HTML-Dateien ansehen, sehen wir, dass jeweils im Titel zum Blogeintrag ein Link zum Volltext steht:
<h2 class="entry-title"><a href="https://www.bubenhofer.com/sprechtakel/2015/08/ ...Wir müssen also aus allen HTML-Seiten diese Zeile extrahieren. Das geht leicht mit grep:
grep -hEo "<h2 class=\"entry-title\"><a href=\"(.+?)\"" *.html > urls.txtDer Suchausdruck ist ein Regulärer Ausdruck und damit sehr flexibel. Wir durchsuchen mit *.html alle Dateien im Verzeichnis, die auf .html enden und schreiben das Ergebnis in urls.txt.
In urls.txt haben wir nun die gewünschten Zeilen, allerdings mit noch etwas zu viel HTML-Code:
<h2 class="entry-title"><a href="https://www.bubenhofer.com/sprechtakel/2015/08/08/coding-cultures-ueber-den- zusammenhang-von-programmiersprachen-und-denkstilen/" <h2 class="entry-title"><a href="https://www.bubenhofer.com/sprechtakel/2015/07/07/tramlinien-vom-bild-zum- textverstehen/" <h2 class="entry-title"><a href="https://www.bubenhofer.com/sprechtakel/2015/05/20/anatomie-eines-textes-bildgebendes -verfahren-fuer-textkorpora/" <h2 class="entry-title"><a href="https://www.bubenhofer.com/sprechtakel/2015/05/18/mooc-sprachtechnologie-in-den- digital-humanities/"
Wir löschen jetzt alles bis und mit href=": - Wir laden die Texte herunter.
Dafür verwenden wir wget, denn damit kann man noch Wartezeiten zwischen dem Download der einzelnen Seiten definieren. Das ist netter für den Server, ansonsten kann es passieren, dass das schnelle Herunterladen von vielen Seiten als Server-Angriff interpretiert und der Zugang geschlossen wird.
wget --random-wait -w 10 -i urls.txtMit -i urls.txt geben wir an, dass alle URLs aus dieser Datei heruntergeladen werden sollen. Mit -w 10 und --random-wait geben wir an, dass wir jeweils zufällige Wartepausen von 0-10 Sekunden einlegen.
perl -pi -e "s/^.+href=\"//" urls.txt
Und noch das Anführungszeichen am Ende:perl -pi -e "s/\"$//" urls.txt
Hier haben wir perl verwendet, um einen Regulären Ausdruck zum Suchen und Ersetzen zu verwenden. Jetzt enthält urls.txt nur noch die gewünschten URLs.
Nun liegen alle Artikel als html-Dateien im Verzeichnis. Nun muss man die HTML-Seiten noch in XML oder txt überführen, was im Kapitel "Von HTML zu XML" beschrieben wird.
| Web: Trafilatura | Medien: Swissdox@LiRI |
| Weitere Korpora | Daten analysieren |
Diese elektronische Ressource soll wie folgt zitiert werden: Bubenhofer, Noah (2006-2025): Einführung in die Korpuslinguistik: Praktische Grundlagen und Werkzeuge. Elektronische Ressource: http://www.bubenhofer.com/korpuslinguistik/.