| Korpora erstellen | Corpus Workbench |
| AntConc | |
Daten analysieren
Hat man das Korpus zusammengetragen und in der Formatierung bereinigt, folgt die eigentliche Analyse. Dazu gibt es natürlich vielfältige Möglichkeiten und für komplexe Fragestellungen können Standard-Analysen höchstens Teil der ganzen Methode sein. Man sollte sich nicht scheuen, auch unkonventionelle Wege zu gehen, jedoch die eigentliche Fragestellung immer im Hinterkopf behalten.Hier wird eine kleine Palette an Analysemöglichkeiten aufgezeigt. Es gibt dafür teilweise Software, die die Analyse unterstützt. Einen Überblick gibt das Softwareverzeichnis. Oft ist man aber genauso gut bedient, wenn man mit einem Texteditor, in dem man mit regulären Ausdrücken suchen kann, oder mit grundlegenden Unix-Befehlen arbeitet. Erfahrene Korpuslinguistinnen und -linguisten erstellen auch oft ihre eigene Programme (z.B. mit Python, wie wir das auf KoDuP-Germanistik zeigen), die genau das machen, was sie wollen.
Konkordanzen
Oft interessiert man sich für den Gebrauch eines Wortes im Korpus. Um dem auf die Spur zu kommen, sind sog. "Concordance"-Programme nützlich. Es gibt einige davon, die auch kostenlos erhältlich sind, z.B.:- AntConc
Konkordanz-Programm, das auch N-Gramme und Wortcluster berechnen kann
Download
Betriebssysteme: Windows, Mac OS X (Installationsanleitung beachten, da X11 nötig!), Linux
kostenlos
Auf der nächsten Seite gibt es eine deutsche Anleitung zur Verwendung von AntConc - ConcApp
Konkordanz-Programm, findet auch Kollokationen
Download
Betriebssystem: Windows
kostenlos - Simple Concordance Program
Erstellt Wortlisten, lässt Korpus durchsuchen etc.
Download
Betriebssysteme: Mac OS X und Windows
kostenlos - Open Corpus Workbench (CWB)
Mächtiges System zur Korpusverwaltung und -recherche, kann im Gegensatz zu den oben aufgeführten Programmen mit annotierten Daten umgehen.
Informationen
Betriebssysteme: Unix/Linux/Mac OS X, Windows
Für Forschung kostenlos
Eine kleine Einführung in die Benutzung der CWB findet sich auf diesen Seiten.
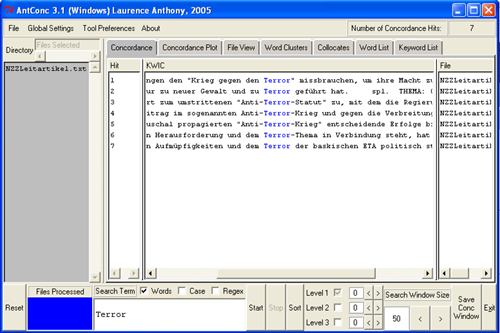
Programme dieser Art können meistens auch noch mehr, z.B. Wortlisten (mit Frequenzen) erstellen oder Kollokationen berechnen.
Wortlisten/Wortgruppenlisten (N-Gramme)
Eine Liste aller vorhandenen unterschiedlichen Wörter mit Angaben zu ihren Frequenzen ist einfach erstellbar und sagt trotzdem schon viel über ein Korpus aus. Die meisten Konkordanz-Programme beherrschen das, ansonsten ist das unter Unix-Systemen (auch Mac OS X) schnell selber gemacht.In die gleiche Kategorie fällt das Berechnen von N-Grammen (Wortgruppen/Kollokationen/Kookkurrenzen). Es gibt verschiedene Methoden, diese zu berechnen. Die einfachste ist, einfach zu zählen, wie oft die unterschiedlichen möglichen Wortkombinationen vorkommen. Auch das können die Konkordanz-Programme meistens oder ist mit Unix-Grundbefehlen machbar. Statistisch komplexere Methoden (wie sie z.B. im IDS-Korpus angewandt werden) beherrschen Spezialprogramme. Besonders empfehlenswert, aber nicht ganz einfach zu bedienen, ist NSP:
- Ngram Statistics Package (NSP)
Berechnung von N-Grammen mittels ausgefeilter statistischer Methoden. Programmiert in Perl, ohne grafische Oberfläche
Download
Betriebssysteme: Mac OS X, Unix-Systeme, Windows
kostenlos
- kfNgram
Programm zur Erstellung von N-Grammen aus Text- oder HTML-Dateien
Download
Betriebssystem: Windows
kostenlos
In diesem Kapitel gibt es eine Anleitung zu kfNgram
Wortarten-Annotation
Oft ist es auch hilfreich, das Korpus vor der eigentlichen Analyse mit morphologischen und syntaktischen Informationen zu annotieren. Ein kostenlos verfügbares und auch für grössere Textmengen einsetzbares Programm ist TreeTagger:- TreeTagger
Werkzeug zur Annotierung von Texten mit Wortart- und Lemma-Informationen (sprachunabhängig)
Download
Betriebssysteme: Mac OS X, Unix/Linux, Windows
kostenlos
Für Windows gibt es für den TreeTagger eine grafische Benutzeroberfläche von Ciarán Ó Duibhín, ebenso für Mac OS X mit dem CasualTreeTagger von Yasu Imao aus Osaka. Für die Benutzung unter anderen Betriebssystemen muss man aber auf die Shell zurück greifen.
In In diesem Kapitel wird erklärt, wie man eigene Daten mit dem TreeTagger annotieren kann.
Der ebenso vom IMS der Universität Stuttgart entwickelte RFTagger liefert im Gegensatz zum TreeTagger noch feinkörnigere morphosyntaktische Informationen, nämlich Kasus, Genus, Numerus und differenziertere Wortarten:
- RFTagger
Werkzeug zur Annotierung von Texten mit feinkörnigen Wortart- und Lemma-Informationen (sprachunabhängig, trainiert für Deutsch, Tschechisch, Slowenisch und Ungarisch)
Download
Betriebssysteme: Mac OS X, Unix/Linux
kostenlos
Auf dieser Seite erklären wir, wie mit Promethia und Python Daten annotiert werden können.
| AntConc | |
| Korpora erstellen | Corpus Workbench |
Das Copyright dieses Kurses liegt bei Noah Bubenhofer. Bei Zitaten oder Verweisen darauf, freut der Autor sich über
eine Mitteilung.
Ebenso bei Fehlern und anderen Hinweisen!
Diese elektronische Ressource soll wie folgt zitiert werden: Bubenhofer, Noah (2006-2024): Einführung in die Korpuslinguistik: Praktische Grundlagen und Werkzeuge. Elektronische Ressource: http://www.bubenhofer.com/korpuslinguistik/.
Diese elektronische Ressource soll wie folgt zitiert werden: Bubenhofer, Noah (2006-2024): Einführung in die Korpuslinguistik: Praktische Grundlagen und Werkzeuge. Elektronische Ressource: http://www.bubenhofer.com/korpuslinguistik/.