
Keine Frage: Word Embeddings sind eine feine Sache, um im Sinne einer distributionalen Semantik semantische Räume zu modellieren. Es besteht aber die Gefahr, einer strukturalistischen Logik zu verfallen und das eigentliche Potenzial zu verschenken.
In unserer Gruppe „Digital Linguistics“ stecken wir mitten in vielversprechenden Experimenten zu Word Embeddings vor dem Hintergrund eines diskurs- und kulturlinguistischen Interesses. Dazu möchte ich ein Beispiel geben.
Was sind Word Embeddings? Sehr kurz gefasst geht es darum, die alte Idee der Kollokationsanalysen zu systematisieren: Für jedes Wort in einem Korpus wird erfasst, mit welchen anderen Wörtern es vorkommt. Ein solches Kollokationsprofil wird nun als Zahlenvektor dargestellt. Nehmen wir vereinfacht an, wir sehen, dass „Tür“ oft zusammen mit „Haus“ und „öffnen“ (sagen wir: 20 und 31 Mal), eher selten aber mit „Tisch“ und „essen“ (5 und 3 Mal), sowie „Brot“ mit oft mit „Tisch“ und „essen“ (25 und 28 Mal), selten aber den anderen zwei Wörtern (10 und 3 Mal) vorkommt, ergibt sich folgende Tabelle:
| Haus | Tisch | essen | öffnen | |
| Tür | 20 | 5 | 3 | 31 |
| Brot | 10 | 25 | 28 | 3 |
| … |
„Tür“ kann nun mit einem Zahlenvektor Tür = { 20, 5, 3, 31} und „Brot“ mit Brot = { 10, 25, 28, 3} ausgedrückt werden. Das sind sozusagen die Fingerabdrucke der beiden Wörter. Diese Fingerabdrucke werden über neuronales maschinelles Lernen in großen Textkorpora erzeugt (also nicht bloßes Addieren der Kollokatoren, sondern ein Lernen der typischen Verwendungsweisen über mehrere verborgene Schichten – eben sog. „Deep Learning“).
Ein Zahlenvektor kann in einem Koordinatensystem dargestellt werden. Nehmen wir an, wir würden von „Tür“ und „Brot“ nur das Vorkommen mit „Haus“ und „Tisch“ messen, könnten wir die Vektoren zweidimensional darstellen:
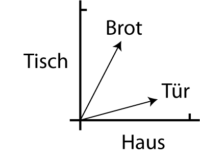
„Tür“ kommt also häufiger mit „Haus“ und seltener mit „Tisch“ vor; bei „Brot“ ist es umgekehrt. Die Vektoren zeigen im zweidimensionalen Vektorraum die Positionen der beiden Ausdrücke.
Und jetzt kommt der eigentliche Witz: Wenn zwei Vektoren in eine ähnliche Richtung zeigen, dann bedeutet das, dass die beiden Wörter ähnlich verwendet werden, also potenzielle Synonyme sind. Die Distanz zwischen den Vektoren kann geometrisch berechnet werden. Da wir normalerweise natürlich nicht nur mit zwei Dimensionen (also zwei potenziellen Kollokatoren), sondern mit sehr vielen (z.B. allen anderen Wörtern im Korpus) rechnen, ergibt sich halt ein n-dimensionaler Vektorraum, der nicht mehr einfach so dargestellt werden kann. Die Berechnung der Distanzen funktioniert aber genau so wie im zweidimensionalen Raum.
Rechnet man nun also von einem großen Korpus ein solches Word-Embedding-Modell, kann zu einem darin vorkommenden Wort abgefragt werden, welche anderen Wörter im Vektorraum in der Nähe stehen – also ähnlich verwendet werden. Das funktioniert sehr gut: In meinem Geburtsberichte-Korpus sind die nächsten Nachbarn zu „Hebamme“ etwa (in Klammern: Nähe – je höher, desto näher):
Hebamme: Hebi (0.9321193099021912), Hebammenschülerin (0.766809344291687), Hebame (0.7523912191390991), Habamme (0.7454160451889038), Ärztin (0.7398992776870728), Hebis (0.7237089276313782), Nachthebamme (0.7169431447982788), Nachthebi (0.6960358023643494), hebi (0.6955133080482483), Claudine (0.6929936408996582)
Wir finden also andere Schreibweisen (sogar selten vorkommende Verschreiber wie „Habamme“), aber natürlich auch Ausdrücke wie „Ärztin“ oder „Claudine“, die natürlich keine Synonyme sind, aber – und darin zeigt sich nun das Potenzial für diskurs- und kulturanalytische Fragestellungen – in diesen Daten ein funktionales Äquivalent.
Schauen wir uns das an einem Beispiel genauer an: Ich habe nun weiter mit dem Word-Embedding-Modell gearbeitet.
- Zunächst habe ich das ganze Modell geclustert unter Verwendung eines K-means-Algorithmus. Ziel: Gruppen von Wörtern identifizieren, die alle ähnlich verwendet werden (also etwa alle Bezeichnungen für Hebammen). Das Modell umfasst gut 16.000 Types und ich rechnete mit verschiedenen Clusteranzahlen von 500 bis 5000. Bei 2000 Cluster ergeben sich also Gruppen, die im Schnitt acht Types umfassen.
- Für jeden Cluster berechnete ich den Zentroiden, also den Punkt, der genau in der Mitte dieser Punktwolke liegt. Von diesem Punkt ausgehend suchte ich die drei am nächsten liegenden Wörter im Modell (da praktisch nie ein Wort tatsächlich genau an diesem Punkt liegt). Diese drei Wörter müssten also ganz gut das semantische Spektrum des ganzen Clusters repräsentieren.
Ein Beispiel: Das Clustering ergab folgenden Cluster, wobei die fettgedruckten dem Zentroiden am nächsten liegen:
Durchatmen, Dösen, Einschlafen, Hyperventilieren, Ruhepause, Sekundenschlaf, hindurch, immerwieder, manchmal, rauben, sogar, totmüde, wegdösen, weggedämmert, weggedöst, weggenickt, zeitweise, zwischen
Der Cluster macht schon mal deutlich: Ganz sicher haben wir es bei dieser Gruppe nicht mit Synonymen im strukturalistischen Sinn zu tun. Aber in den Geburtsberichten sind eben z.B. „zeitweise“ oder „immerwieder“ typisch genau dafür, die körperliche Erschöpfung während der Geburt auszudrücken. Diskursiv gesehen handelt es sich eben um funktionale Äquivalente – oder wie man das auch immer bezeichnen will.
Und nun kommt noch ein entscheidender Schritt hinzu: Mich interessierte nun, an welchen Stellen in den Geschichten zwischen Anfang und Ende die einzelnen Cluster gehäuft vorkommen (dies geht auf das Interesse zurück, narrative Muster in den Geschichten zu entdecken). Für alle Mitglieder eines Clusters werden dazu die relativen Positionen in den Geschichten aufsummiert. Das folgende Diagramm zeigt nun genau dies für eine Reihe von Clustern mit Personen/Rollenbezeichnungen:
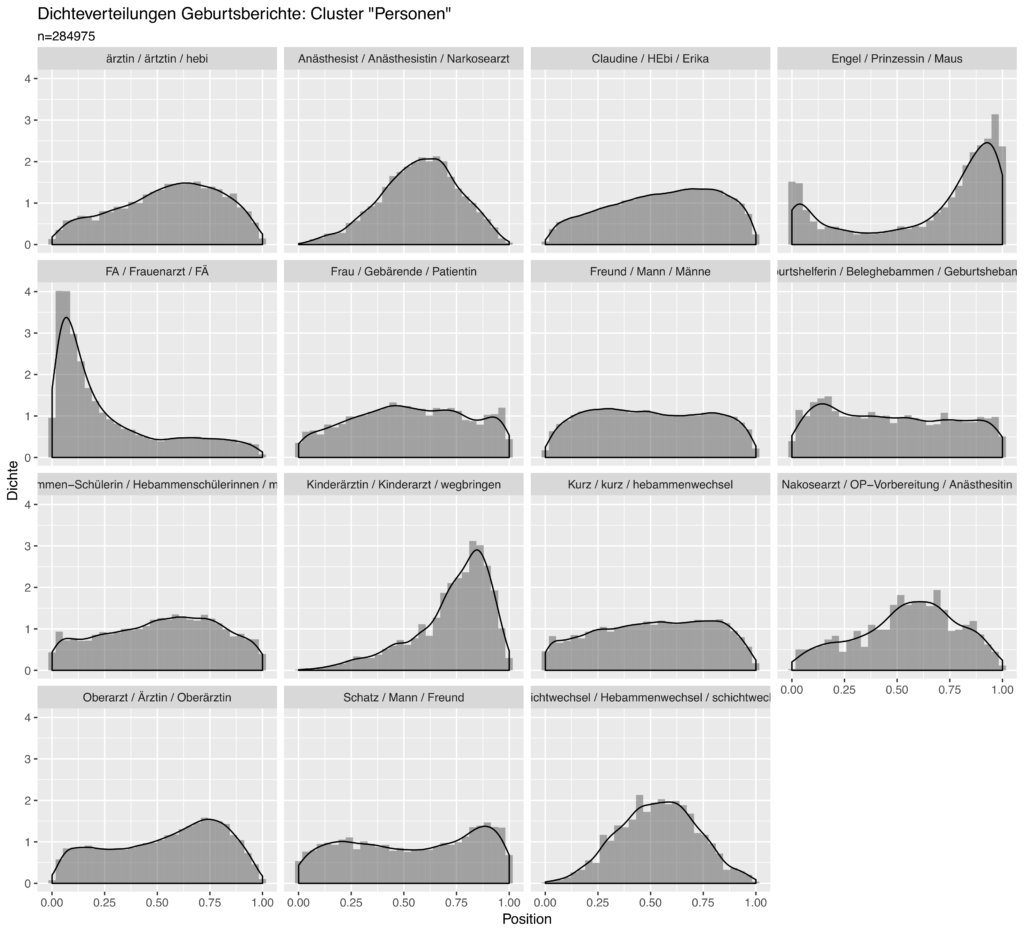
Jedes Diagramm zeigt einen Cluster, wobei jeweils die drei dem Zentroiden nächsten Ausdrücke im Titel genannt werden. Die Grafiken zeigen die Häufigkeitsverteilungen über die Geschichten. So sieht man etwa, dass Ausdrücke für Frauenarzt (FA, FÄ) praktisch nur am Anfang der Geschichten eine Rolle spielen, die Kinderärztin (inkl. dem damit verbundenen Verb „wegbringen“!) am Ende.
Und wo sind die Hebammen? Im Cluster „Claudine / Hebi / Erika“! Der Cluster fällt auf durch eine Reihe von Vornamen, die alle typisch für Frauen zwischen 40 und 60 zu sein scheinen. Denn es ist klar, dass in den Geburtsgeschichten auf die Hebamme sehr oft mit ihrem Vornamen referiert wird, was ein Zeichen für die Nähe der Gebärenden (bzw. Erzählenden) zu ihr ist. Alles andere medizinische Personal kommt mehrheitlich mit Funktionstiteln vor.
Ich breche hier ab und hoffe, das Potenzial für Word Embeddings gezeigt zu haben, wenn man sie für ein diskurs- und kulturlinguistisches Interesse fruchtbar macht. Mehr dazu wird es in folgender Publikation geben:
Bubenhofer, Noah (eingereicht): Semantische Äquivalenz in Geburtserzählungen: Anwendung von Word Embeddings. Zeitschrift für Germanistische Linguistik.