
Ich wundere mich noch immer darüber, dass viele meiner Mitmenschen die Dimension der Snowden-Enthüllungen der Digitalüberwachung durch die Geheimdienste nicht erfassen. Die Vorstellung des „ich habe ja nichts zu verbergen“ ignoriert, dass es nicht darum geht, ein paar böse Botschaften im Netz zu erfassen, sondern über die Analyse der digitalen Spuren unseres Handelns uns alle unter Generalverdacht zu stellen. Und „Analyse“ bedeutet nicht, E-Mails mit einer Liste von gefährlichen Schlagwörtern abzugleichen, sondern das ganze Know-how statistischen Data Minings und maschineller Textanalyse einzusetzen, um ungewöhnliche Muster in gigantischen Datenmengen datengeleitet aufzuspüren.
Methodisch ist das hoch interessant und als Korpuslinguist versuche ich im Grunde nichts anderes zu machen. Allerdings mit anderem Erkenntnisinteresse als die Geheimdienste und geleitet von einem ethischen Codex – und mit öffentlich verfügbaren Daten. Wenn man das macht, ist jedoch ziemlich klar, was technisch möglich ist und die Dienste demnach wohl auch machen. Es ist wichtig, dieses Wissen öffentlich zu machen, damit wir Bürgerinnen und Bürger uns bewusst sind, was im Geheimen gemacht wird um entscheiden zu können, ob wir das politisch wirklich wollen.
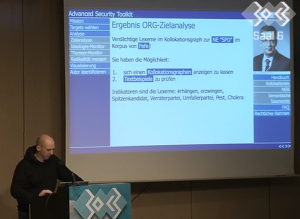 Mein Kollege josch hat am 30. Chaos Communication Congress einen wunderbaren Vortrag zum Thema „Überwachen und Sprache“ gehalten, den ich mit Nachdruck empfehle, sich anzusehen! Er demonstriert anhand eines fiktiven „Advanced Security Toolkits“ zur automatischen Sprachanalyse, was heute linguistisch-statistisch möglich ist und wo die Probleme und Gefahren liegen.
Mein Kollege josch hat am 30. Chaos Communication Congress einen wunderbaren Vortrag zum Thema „Überwachen und Sprache“ gehalten, den ich mit Nachdruck empfehle, sich anzusehen! Er demonstriert anhand eines fiktiven „Advanced Security Toolkits“ zur automatischen Sprachanalyse, was heute linguistisch-statistisch möglich ist und wo die Probleme und Gefahren liegen.


{kind=link}