
Jedes Geburtserlebnis ist einzigartig. Als Mann habe ich wahrscheinlich nicht mal einen Hauch von Ahnung, wie es sich anfühlt, ein Kind zur Welt zu bringen.
Ich habe jedoch eine Ahnung davon, wie solche Geburtserlebnisse erzählt werden. Und sie werden massenhaft erzählt, auf Online-Diskussionsforen zu Themen der Mutterschaft (und Vaterschaft). Eine solche ganz durchschnittliche Erzählung lautet etwa so:
An diesem Tag hatte ich… → …, dass es endlich losgeht → ich hatte das Gefühl, dass… → Mein Mann und ich waren… → war mich sicher, dass… → auf den Weg in die… → Ich sagte ihr, dass… → so heftig, dass ich… → fühlte sich an, als → war ich fix und fertig → Ich hatte das Gefühl, → dass es nicht mehr lange… → ich dachte, ich muss… → , aber es ging nicht → , was das Zeug hielt → dann ging alles ganz schnell → Ich weiß nur noch… → um 16:38 war es → ich konnte es nicht glauben → ich war so froh… → , dass es vorbei war → ich hätte nie gedacht, → und ich muss sagen, → Für mich war es eine… → noch vor sich haben…
Interessanterweise haben die Autorinnen solcher Texte über ihre Geburtserlebnisse bestimmte Schemen und Wendungen im Kopf, wie ein solches Erlebnis erzählt werden soll. Natürlich gibt es Abweichungen davon, trotzdem ist es verblüffend, wie konventionalisiert die Gattung „Geburtsbericht aus Ich-Perspektive“ als Alltagserzählung ist – die Erzählung über ein Erlebnis, das ja als höchst einzigartig und individuell erlebt wird. Im Folgenden zeige ich ein paar Erkenntnisse einer Analyse von 14.000 Geburtsberichten.
Die Daten stammen aus den einschlägigen Threads (überschrieben mit „Geburtsberichte“ o.ä.) von sechs verschiedenen Webforen und umfassen gut 12 Mio. Tokens in 14.000 Texten. Für die weiteren Analyse berücksichtigte ich jeweils nur den ersten Post, in dem normalerweise der eigentliche Bericht steht, während die Antworten dazu die Kommentare von Leserinnen sind (ich verwende hier nun mal das generische Femininum, etwaige Männer sind mitgemeint). Hier die Angaben zum Korpus:
| Forum | # Wörter | # Texte |
|---|---|---|
| http://www.urbia.de/ | 7.364.108 | 8808 |
| http://www.babyforum.de/ | 2.089.936 | 1824 |
| http://www.parents.at/ | 1.199.174 | 1647 |
| https://www.swissmomforum.ch/ | 1.156.193 | 919 |
| http://www.eltern.de/ | 438.017 | 716 |
| http://www.umstandsforum.de/ | 289.807 | 568 |
| Total | 12.537.235 | 14.482 |
Manchmal erstreckt sich eine Geschichte über mehrere Posts, meistens aber nicht, deshalb verzichtete ich auf eine exaktere Datenextraktion.
Nun berechnete ich wie gewohnt typische Mehrworteinheiten im Korpus im Vergleich zu einem allgemeinen Pressekorpus. Neu ist aber, dass wir nun für jede dieser Mehrworteinheiten wissen, an welchen relativen Positionen der Geschichten sie auftritt – der Anfang der Geschichte ist 0, das Ende 1. Für jede Mehrworteinheit kann man dann Mittelwerte und Streuung der Positionen berechnen, so etwa für „dann ging alles ganz schnell„, das im Durchschnitt an Position 0.7 vorkommt, also gegen Ende der Geschichte.
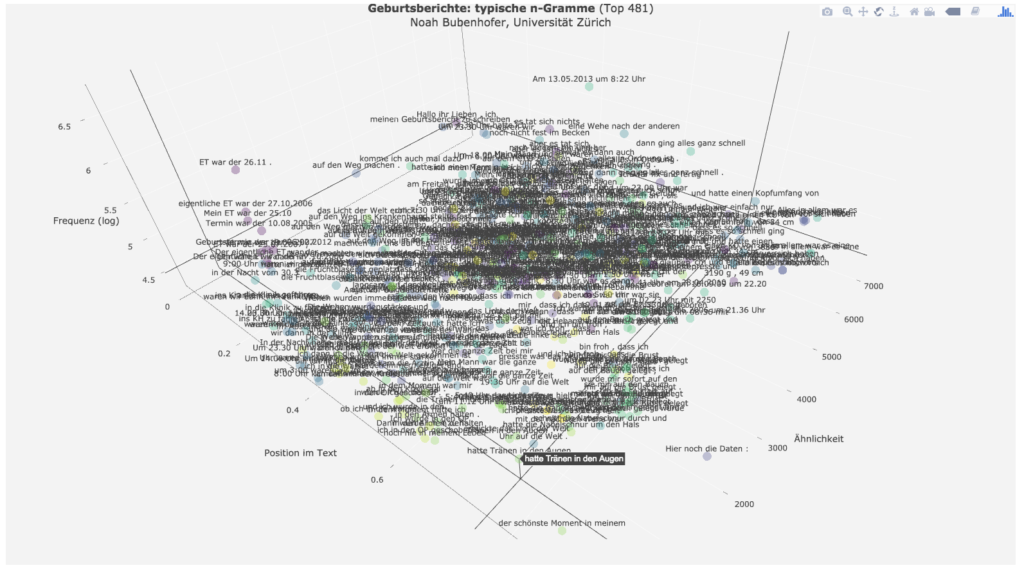
Zur Analyse der Daten wählte ich eine dreidimensionale, interaktive Darstellung – hier als Screenshot:
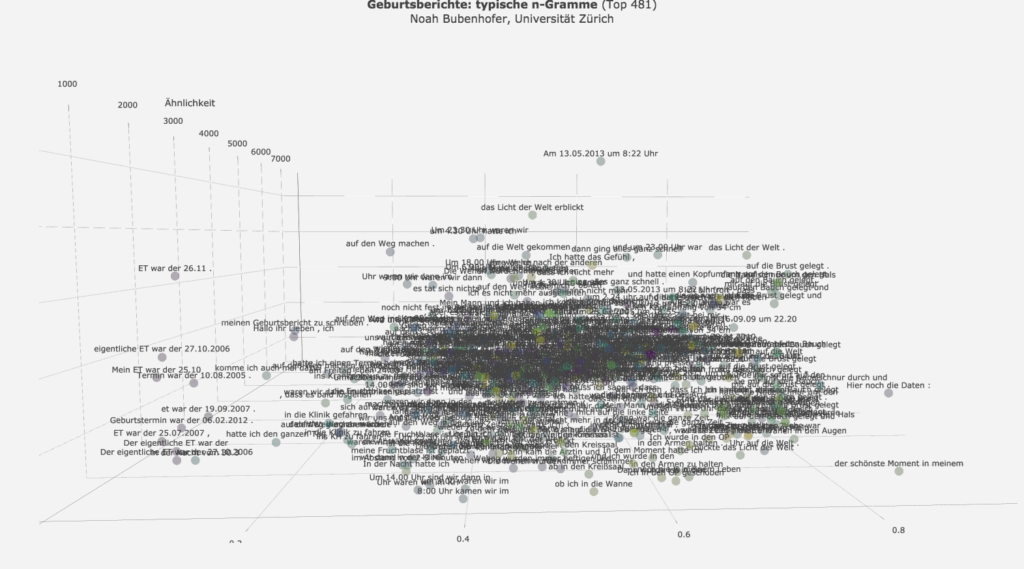
Hier kann man selber die interaktive Version anschauen (2.6 MB, ggf. lange Ladezeit). Es gibt drei Dimensionen:
- x-Achse: Mittlere Position der Mehrworteinheit in der Geschichte
- y-Achse: Frequenz der Mehrworteinheit (logarithmisierte Skala)
- z-Achse: Ordnung nach Ähnlichkeitsrang
Basis des Ähnlichkeitsranges ist eine Clusteranalyse, um ähnliche Mehrworteinheiten (dann ging es auch schon, und dann ging es auch, ging es auch schon los, und dann ging es auch schon…) gruppieren zu können.
Bei der Arbeit mit dem Diagramm kann der Fokus nun auf jeweils zwei Achsen gelegt werden, indem es entsprechend gedreht wird. Die Darstellung oben zeigt die Distribution der Mehrworteinheiten über die typischen Positionen in den Geschichten, wobei die häufigsten im oberen Bereich liegen. Wenn man die Darstellung leicht kippt, kriegt man die z-Achse für die Ähnlichkeitsränge besser in Sicht. Der statische Screenshot gibt den Vorteil der dreidimensionalen Darstellung nur unzureichend wieder.
Bei der folgenden Ansicht sieht man nun besser die Gruppen ähnlicher Mehrworteinheiten und ihre Positionen in den Geschichten:
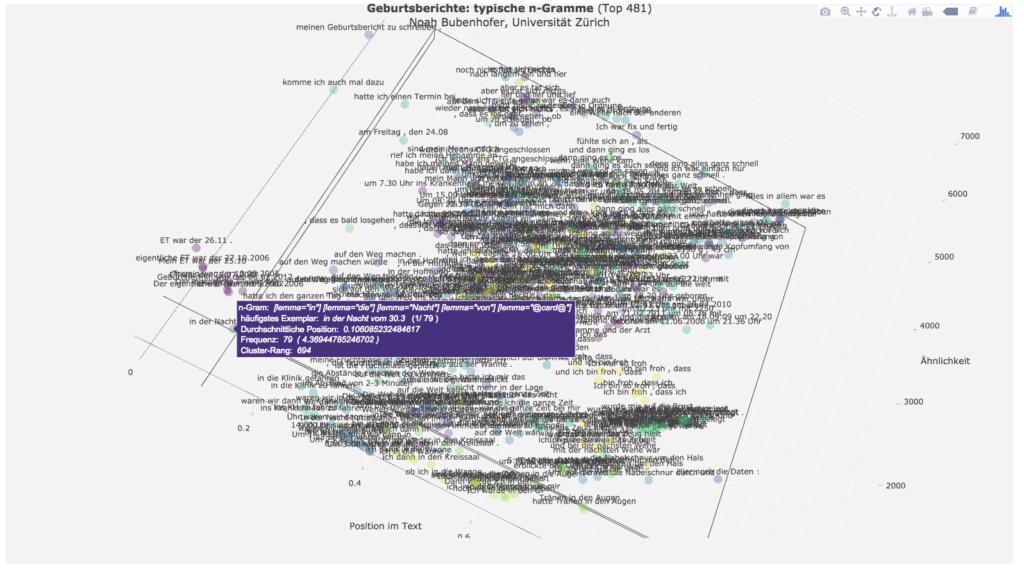
Die Geschichten beginnen also oft mit Mehrworteinheiten zum „ET“, also dem errechneten Geburtstermin und mit „in der Nacht vom DATUM“. Oder die Geschichten beginnen mit der Thematisierung des Erzählens selber: „komme ich auch mal dazu“, „meinen Geburtsbericht zu schreiben“.
Meistens ist dann der Weg ins Krankenhaus Teil der Erzählung, verbunden mit der Benennung der Erwartung, „dass es bald losgehen“ wird.
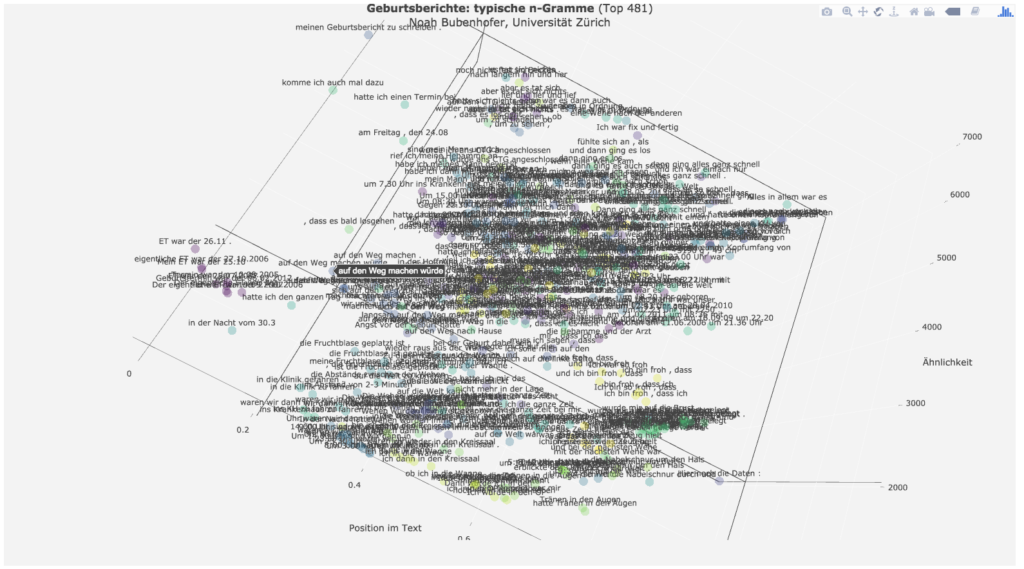
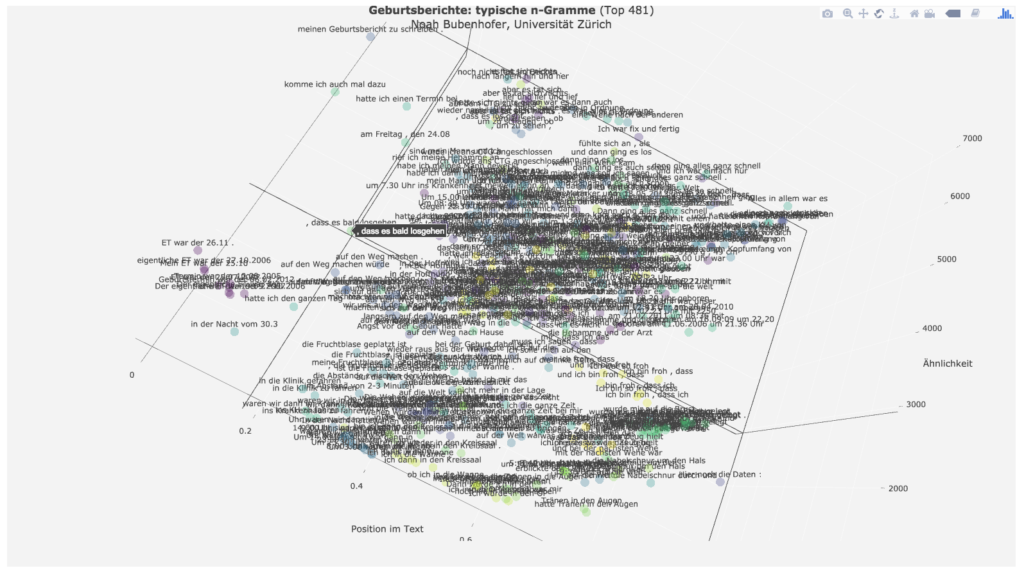
Neben vielen anderen Mehrworteinheiten wird dann häufig mit „die Abstände zwischen den Wehen“ der für das weitere Prozedere relevante Indikator für den Fortgang der Geburt genannt.

Meist vor der eigentlichen Geburt wird ein Moment der Verzweiflung erzählt, z.B. mit „ich war fix und fertig“, „ich kann nicht mehr“, „eine Wehe nach der anderen“, verknüpft mit der Hoffnung „dass es nicht mehr lange dauern [wird]“.

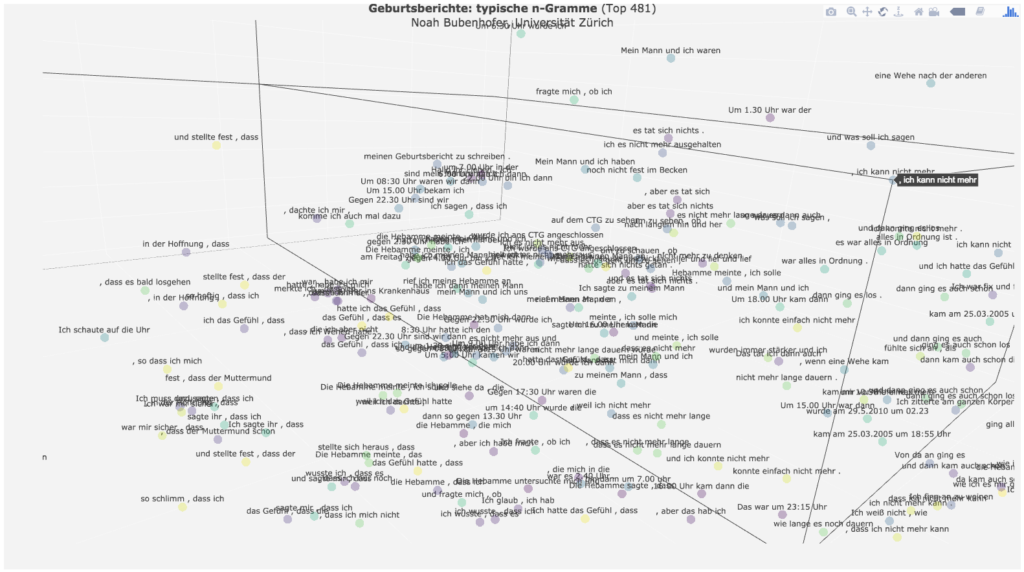
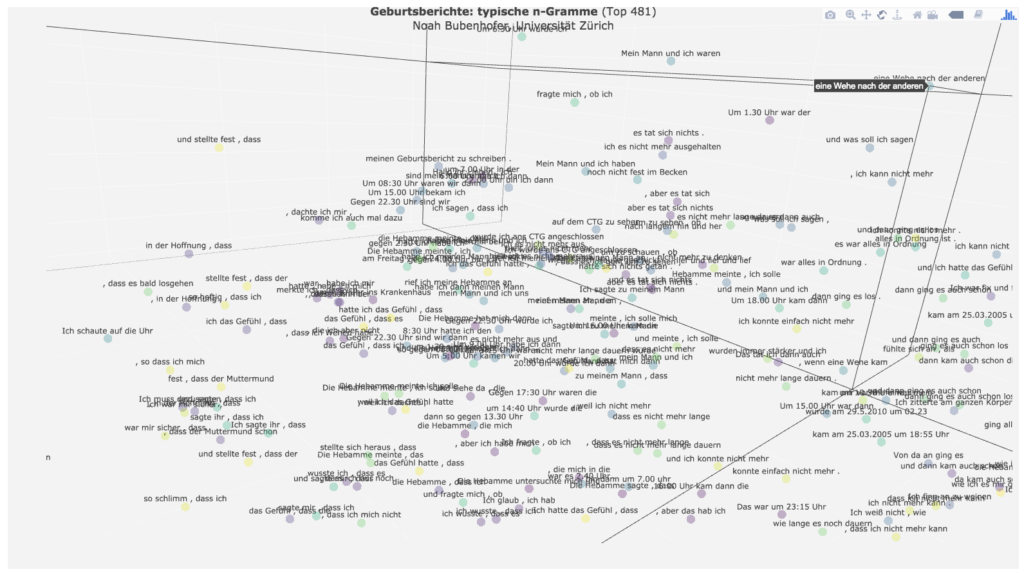
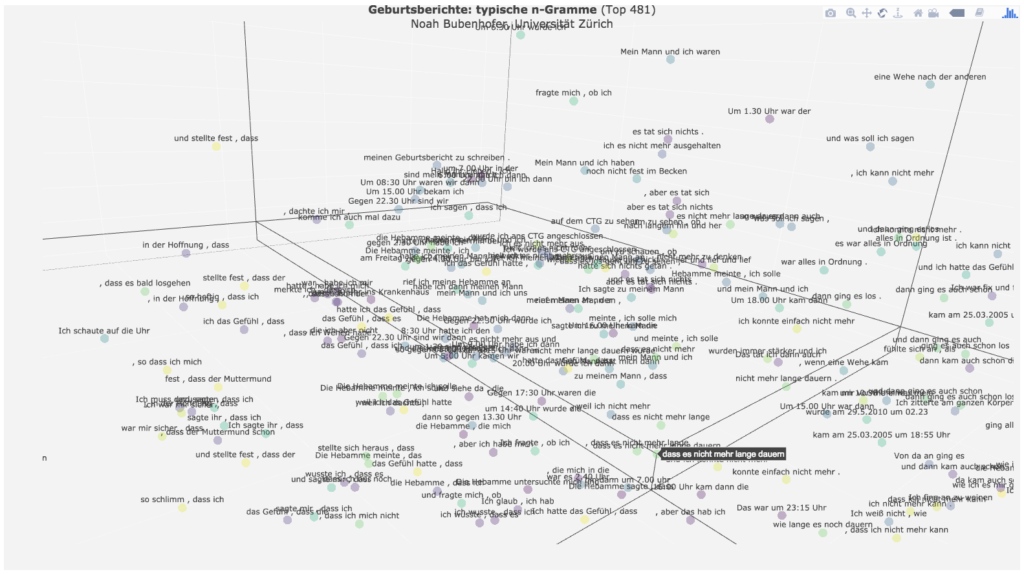
Die Erzählungen enthalten dann häufig ein erlösendes „dann ging alles ganz schnell“, mit dem die Krise des höchsten Schmerzes überwunden wird.

Die einer Geburtsanzeige ähnliche Formel „am DATUM um UHRZEIT“ und „erblickte das Licht der Welt“ (und Varianten) wird dann die eigentliche Geburt des Kindes erzählt.
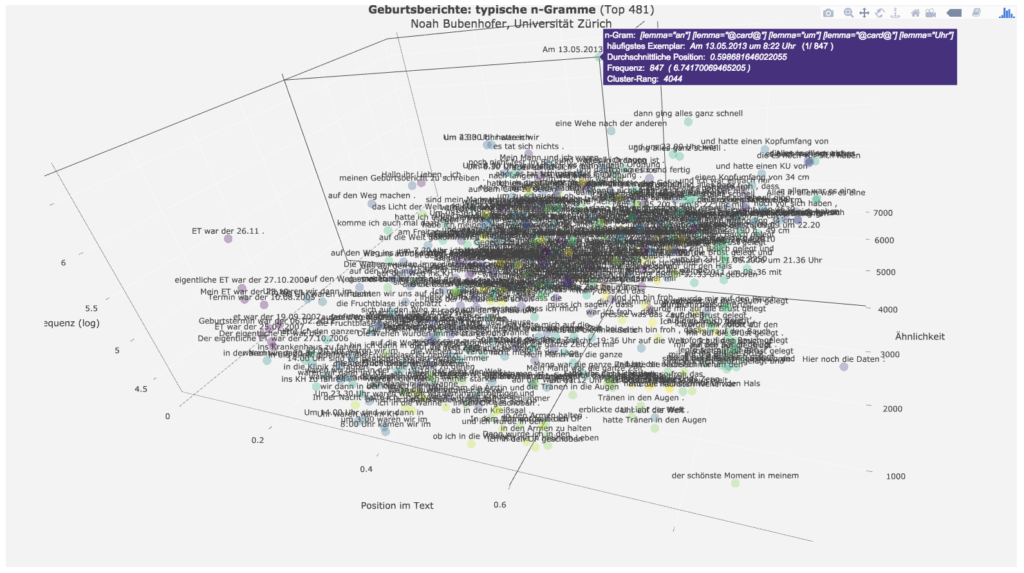
Daran sieht man auch deutlich die erzählerische Rekonstruktion des Ereignisses: Beim tatsächlichen Akt der Geburt ist der Gebärenden wahrscheinlich die genaue Uhrzeit nicht bekannt und für sie auch nicht relevant. In der retrospektiven Erzählung hingegen wird der Moment der Geburt sozusagen als Geburtsanzeige inszeniert.
Auch gegen Ende der Geschichten werden dann zwei weitere wichtige erzählerische Stationen verbalisiert: „ich hatte Tränen in den Augen“ und „sofort auf den Bauch gelegt“ – Momente großer Emotionalität.
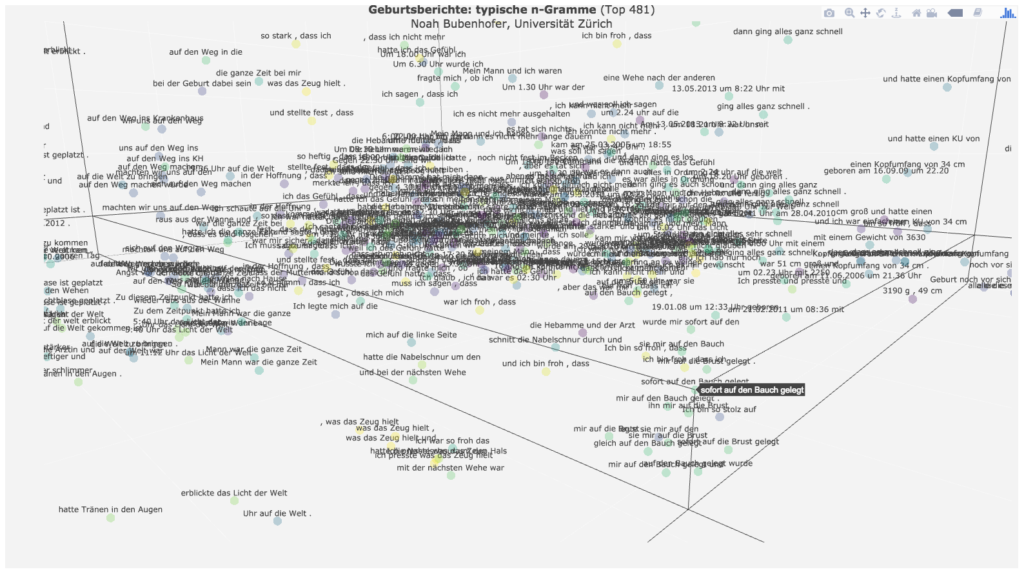
Das immer wieder gewählte Motiv der Erlösung durch die Geburt nach der Krise des größten Schmerzes wird damit durch eine Reihe von Mehrworteinheiten verbalisiert, bevor die Geschichten mit einer Art Evaluation enden: „der schönste Moment in meinem“ und „ich bin froh, dass…“.
Ich bin jetzt nur auf wenige Mehrworteinheiten eingegangen; natürlich sind die Geschichten vielfältiger und es lassen sich noch viele weitere Motive finden. Hier kann man sich gerne selber durch die Geschichten wühlen: http://www.bubenhofer.com/narrviz/geburtsberichte.plot3d.top481.html
Eine ausführliche Fassung erscheint in den nächsten Monaten als wissenschaftliche Publikation.
Zu Beginn bin ich über die ethnokategorielle Gattungsbezeichnung gestolpert. Die Texte werden von den Autor_innen selbst ja als „Geburtsberichte“ bezeichnet und nicht etwa als ‚Geburtserzählungen‘. In welcher Relation sehen Sie diese Gattungsbezeichnung zu Ihrem analytischen Fokus auf Erzählstrukturen?
Ich bin gespannt in der Publikation mehr davon zu lesen!
Liebe Grüße,
Matthias Meiler